 Skip to content
Skip to content
The blog will help to understand the usages of the functions:
- Read PDF Text
- Read PDF with OCR
In UiPath we can extract text data as well as any text present in image form, through the different functions present in the PDF packages provided by UiPath.
For that we have to install the PDF Packages in UiPath. Follow the below steps: –
- Go to Manage Packages and select All Packages
- Type PDF and select UiPath.PDF.Activities
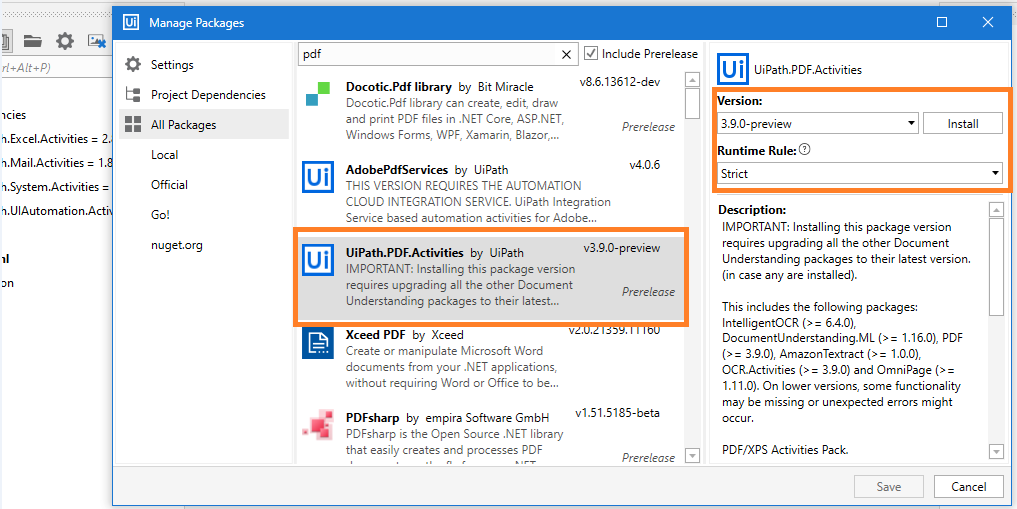
- Install Package UiPath.PDF.Activities.
- The different options for PDF Automation will be available in UiTool once the installation is completed.
Read PDF Text – The section illustrates the Reading and extracting data from PDF to another Text file.
- Under Activities, we start with a sequence. Then write PDF to view all its functions present and Drag and Drop “Read PDF Text”
- We have to give the Input file Path for the PDF to be read. We can store the Output Text into a String Variable.
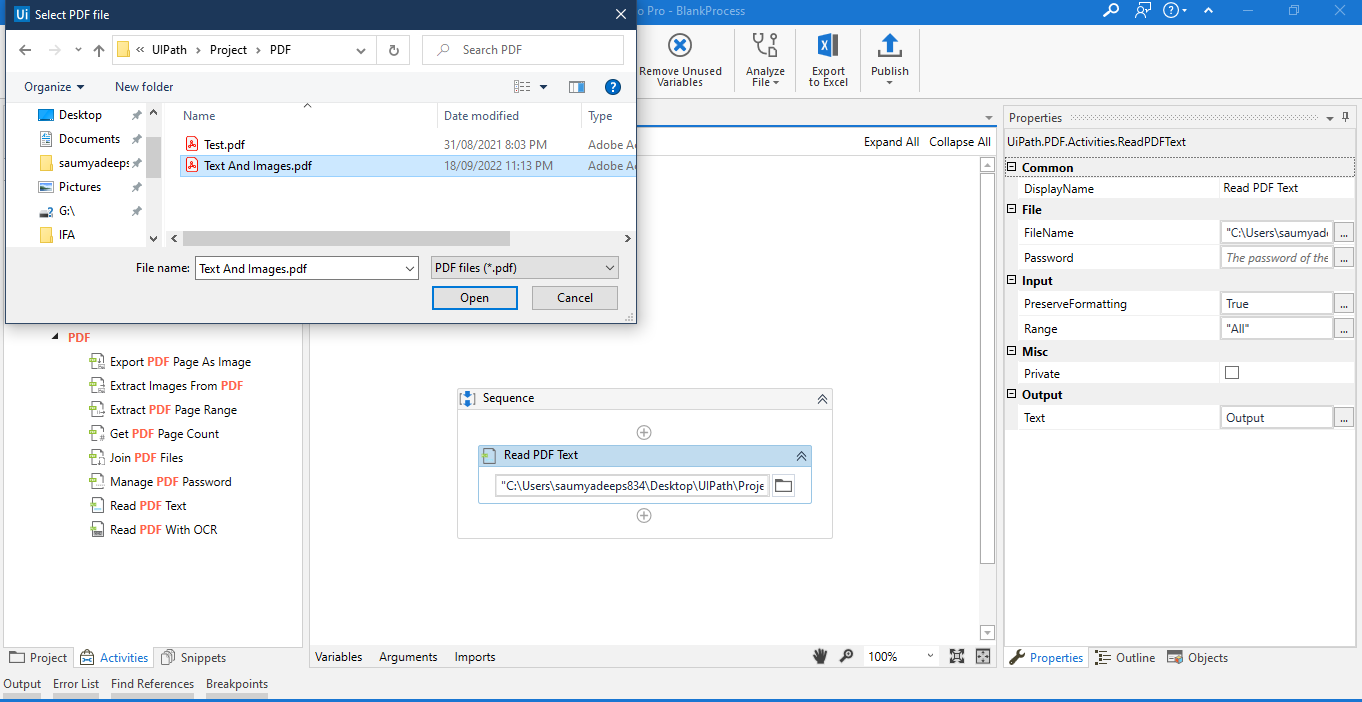
- Now we are writing the Output to a Text file using the Write Text File Activity.
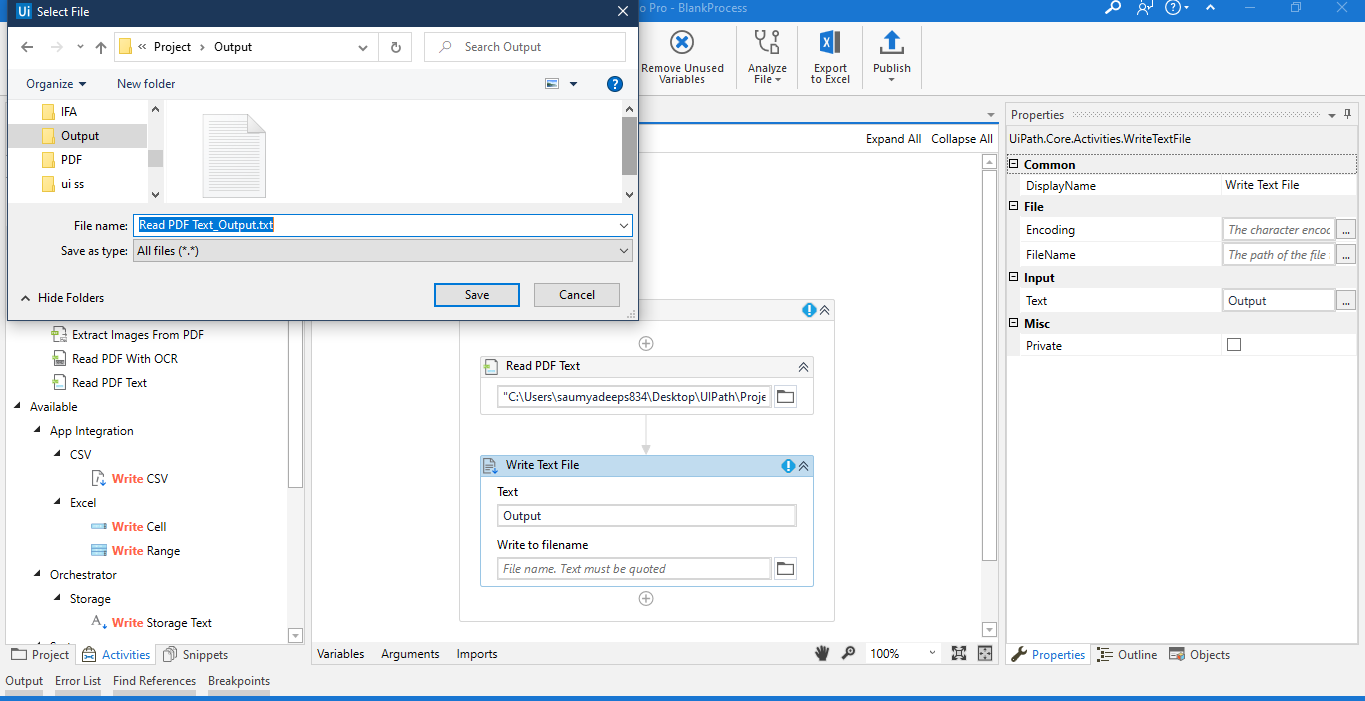
- Under Write Text File we have to give the Input Text as the Variable Name in which we have stored the output in earlier steps. Also, we have to provide the File path where our Output Text File to be created.
- Once we run our Process, we can see the Result as follows.
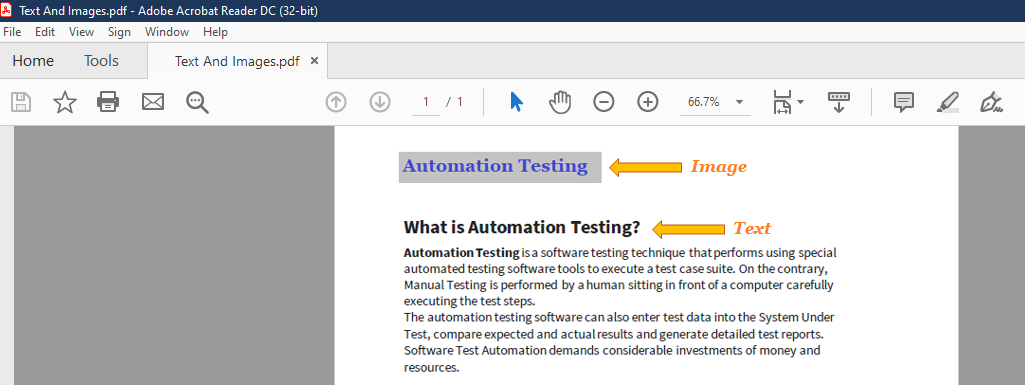

We can see that all the Text from our Input PDF has been successfully extracted to out Output File except the Image that consists of Text. In Order to recognize and extract the Text from Image we have to use the Read PDF with OCR function.
Read PDF with OCR
Our input PDF file consists of an image part which we want to extract too along with other texts.
OCR – optical character recognition is the technology used for distinguishing text character inside digital images. In UiPath we have multiple ways to read a text from an Image. Here we are using the Read PDF with OCR.
For this we have to use an OCR engine. UiPath OCR is a proprietary OCR technology of UiPath, supporting characters used by the following Latin script languages: English, French, German, Italian, Portuguese, Romanian and Spanish. Text in other languages will be recognized but without accents.
The default Engines Provided by UiPath are- Google Cloud Vision OCR, Microsoft Azure Computer Vision OCR,Microsoft OCR,Microsoft Project Oxford Online OCR,Tessaract OCR.
These various engines are used depending on the Document we are using.
Below steps show the Use of OCR to read a PDF
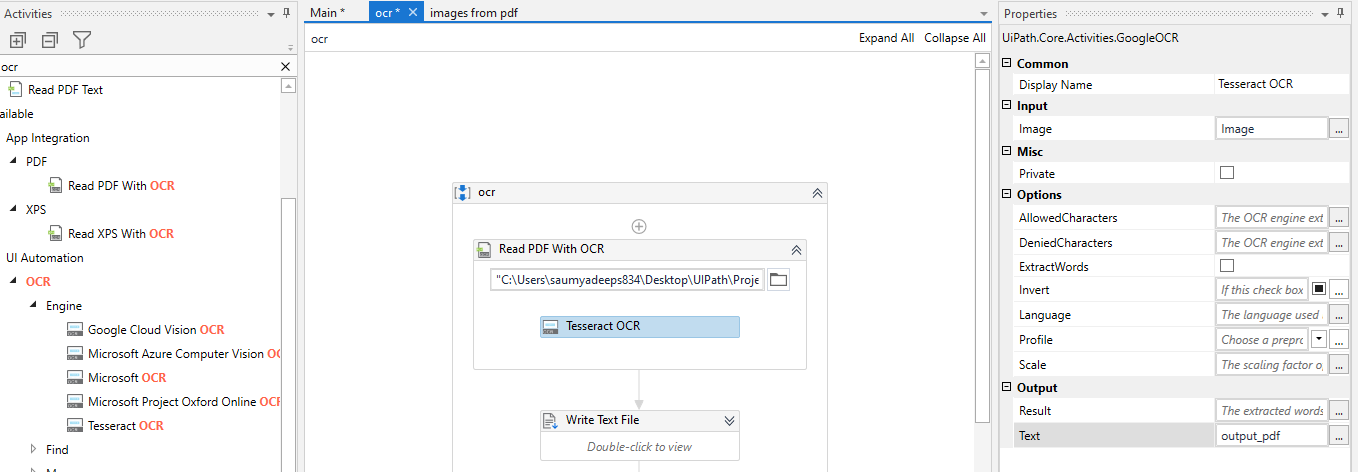
- Under Activities,We start with a sequence. Then write PDF to view all its functions present and Drag and Drop “Read PDF with OCR”
- We have to give the Input file Path for the PDF to be read. We can store the Output Text into a String Variable.
- We have to now search for OCR in activities and Select Any of the OCR.
- We have to enter the output variable for the OCR used.
- Now we are writing the Output to a Text file using the Write Text File Activity.
- Under Write Text File we have to give the Input Text as the Variable Name in which we have stored the output in earlier steps. Also, we have to provide the File path where our Output Text File to be created.
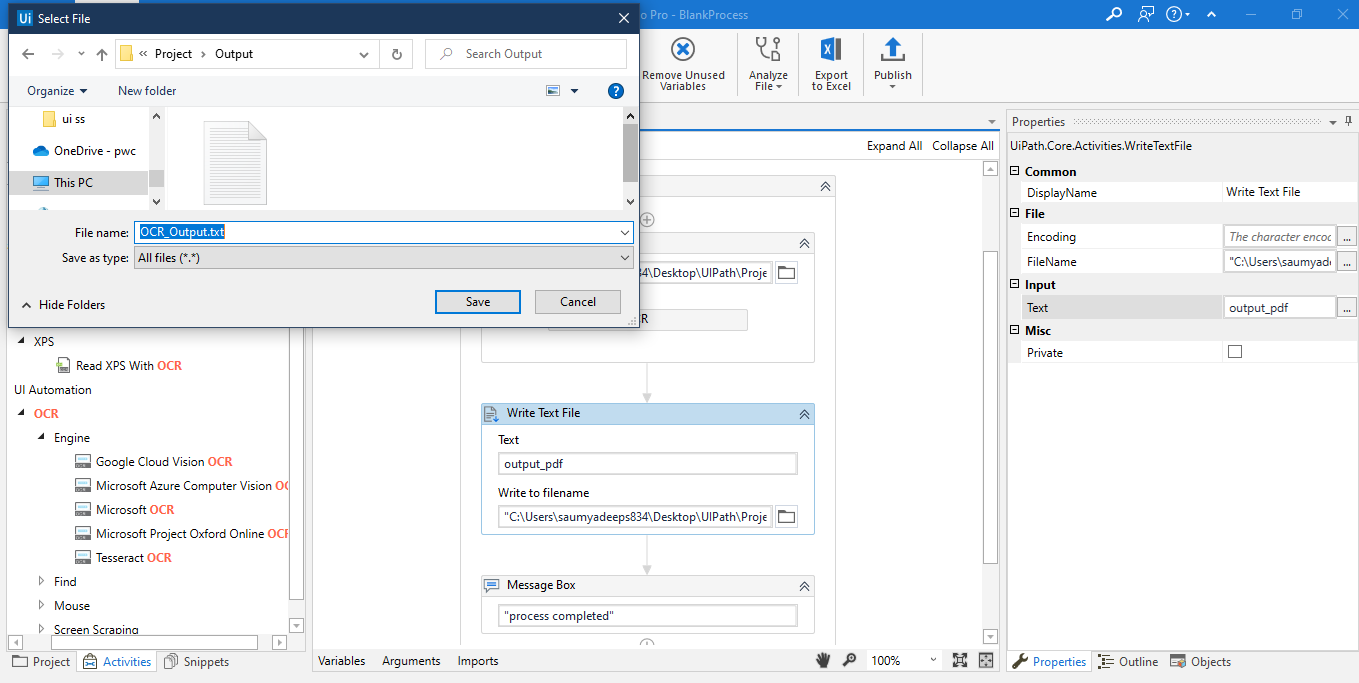
- Once we run our Process, we can see the Result as follows.
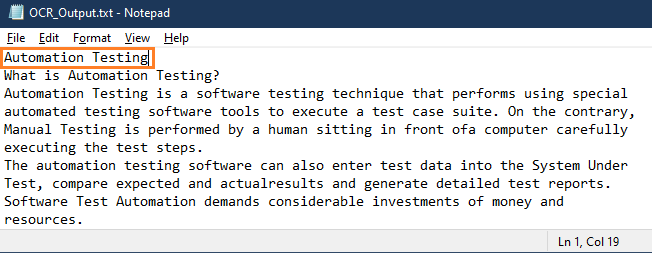
We can see that all the Text from our Input PDF has been successfully extracted to our Output File along with the Text Present in the Image. Both this Activity are self-contained meaning even if the PDFs are not open, they can read as well as extract data.






